众所周知,长毛象3.0.0版本之后便带有了OCR功能。 如今长毛象版本已经到3.1.2了,但是OCR功能在 bgme.bid 域名上仍然无法使用。
这可太不妙了,于是就有了这篇博文。
问题一:bgme.bid 域名无法使用 OCR
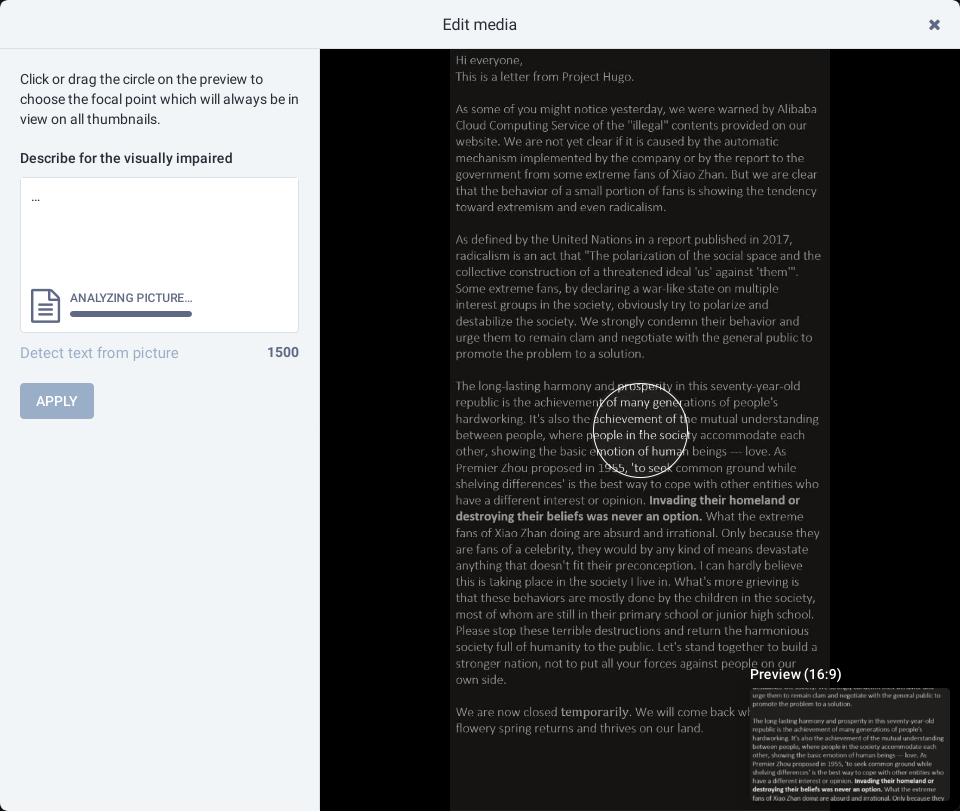
bgme.bid OCR 出问题的截图
问题的开端便是 bgme.bid 域名的 OCR 总是用不了,每次按下 Detect text from picture 按钮后,页面便卡在了那里,从来都没有识别成功过。
我一直以为这是因为长毛象OCR功能有问题,但直到有一天,我发现 nebula 实例的OCR可以正常工作。随后便到 bgme.me 域名试了一下,发现也是可以工作的。 于是按下 F12,查看网络请求。 搞了半天,原来是我的 nginx 设置有问题呀!

bgme.bid 设置有问题
将错误的 nginx 设置修正,问题解决。
问题二:长毛象OCR不能设别中文
虽然前一个问题解决了,但是紧接着又发现了新问题。长毛象的OCR竟然不能识别中文。
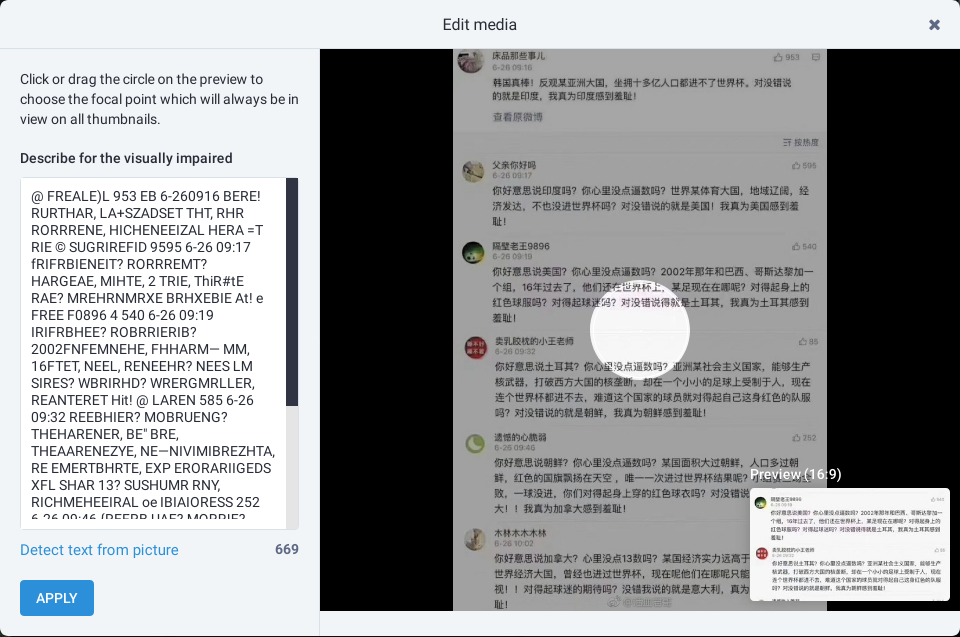
识别中文文本返回乱码
这个问题有一点难办,到 mastodon 主线用相关关键词搜索一番,并没有找到什么有用的信息,识别中文乱码这件事根本就没有人反馈。
中文长毛象用户就这么少吗?
或者就我一个人遇到了这个问题?抑或者说,大家根本就不用OCR功能?
既然没能找到相关的issue,那就只能翻代码了。
找到添加OCR功能的那个PR。 从这个PR中可以看出,Mastodon的客户端OCR是利用 tesseract.js 实现的。
找到 Mastodon OCR实现的相关代码, 对照 tesseract.js文档。
我们可以发现 Mastodon 的OCR并没有显式的指出语言,因此默认采用英语进行识别。
Mastodon 的 lang-data 目录 ,
只有 eng.traineddata.gz 一个文件也从侧面证实了我的看法。
综上,要解决中文OCR乱码问题,只需要在OCR识别相关代码中指出识别语言,同时在 lang-data 目录下添加相应的训练模型即可。
各种语言的识别模型可以从这里下载。